Back to top: The Urkesh Corpus
Chronological spread
The Urkesh corpus consists for the most part of excavated ceramics from all areas excavated on the High Mound and the Outer City. The earliest well stratified material comes from the Temple Terrace where we excavated a niched building, presumably a temple. The surrounding contexts yielded ceramics and seal impressions from the mid-fourth millennium B.C. (Late Chalcolithic 3). Earlier evidence from the fifth millennium Halaf period came from scattered deposits, but no stratified contexts except from a small, deep sounding (S2) on the northeast portion of the High Mound.
The site was intensly occupied in the Early Dynastic III period when the monumental Temple Terrace and the numerous stratified contexts connected with it yielded a large amount of ceramics as well as seal impressions. Ceramics from well stratified contexts dating to the Akkadian through the Mittani periods are abundantly represented.
The final period of use at the site was the Middle Assyrian period but we have excavated few stratified contexts connected with this time frame resulting in a ceramic corpus that does not fully represent the probable breadth of the ceramics produced and used at Urkesh during this period.
All these ceramics are reflected in the Horizon portion on the right hand side of the book.
Back to top: The Urkesh Corpus
Data set
The chart below displays separately the number of both body sherds and shape sherds analyzed from selected excavation units. From these units we have completed the analysis of 345,867 sherds (not including ceramic items and q-items). These numbers in the charts in this section were current in 2017 but may have changed because of ongoing checking.
While not all the units are represented in the present version of the Ceramics Book, the ceramic analysis has been completed but the checking is still underway. When this is finished they will be available in individual unit books which will be opened as soon as the stratigraphic analysis is completed.
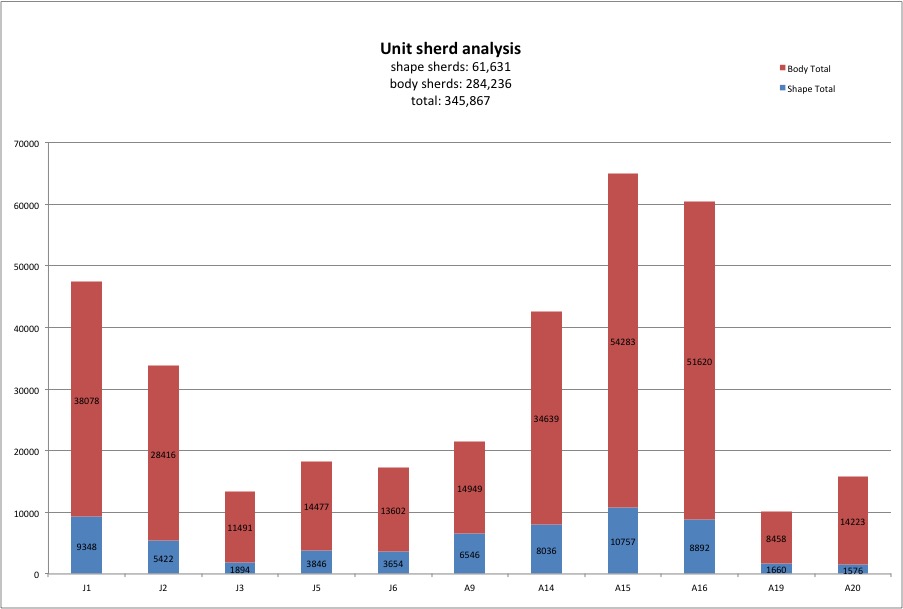 2. Analyzed sherds from selected units (August 2017, L. Recht)
2. Analyzed sherds from selected units (August 2017, L. Recht)
Back to top: The Urkesh Corpus
Quantitative analysis
To give an idea of how data are treated in the individual unit books one may consider the following.
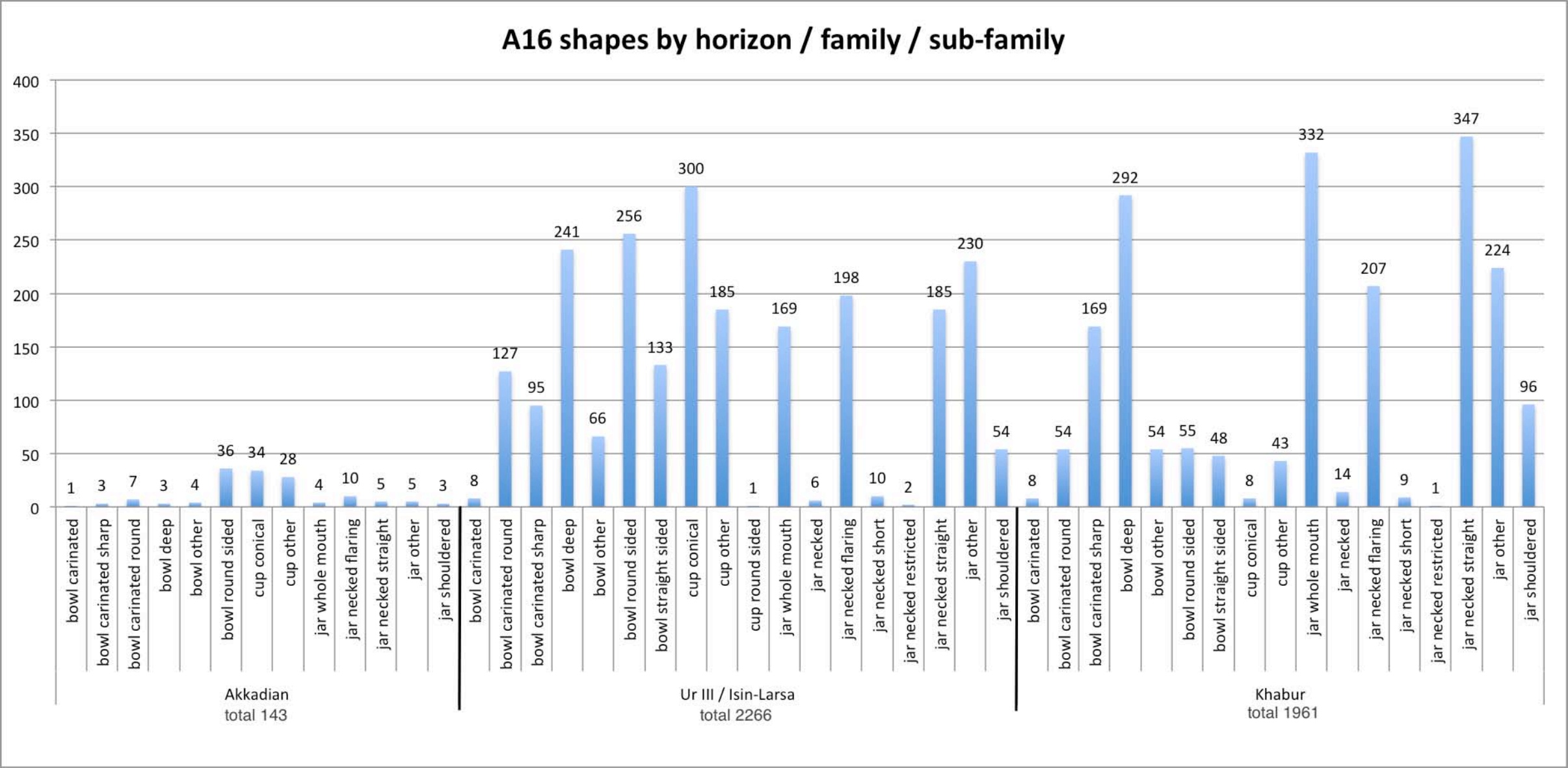
The average quantity of sherds found every excavation season is about 40,000 sherds per season. While this is typical for Syro-Mesopotamian sites dating to historic periods, it is not typical that all the sherds are analyzed and published. A sample of this effort can be seen in the charts of ceramics excavated in one excavation unit, A16.
The first chart shows the body and shape sherds from three major horizons sported by ware type: the Akkadian, Ur III/Isin-Larsa and the Khabur periods, for a total of 55,055 sherds.
The other three charts deal with shape sherds, with an increasing degree of specification: overall, by family and by sub-family
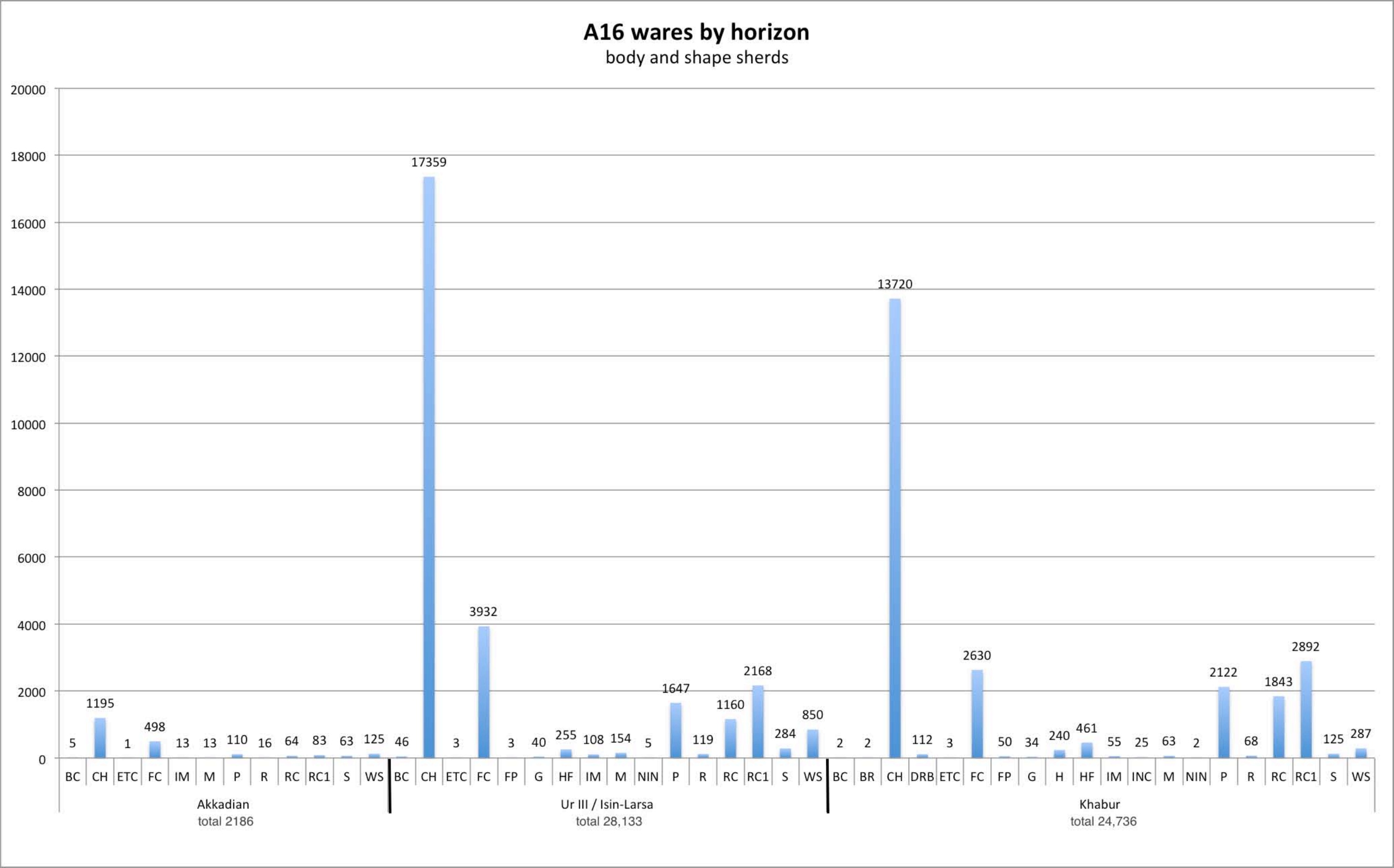
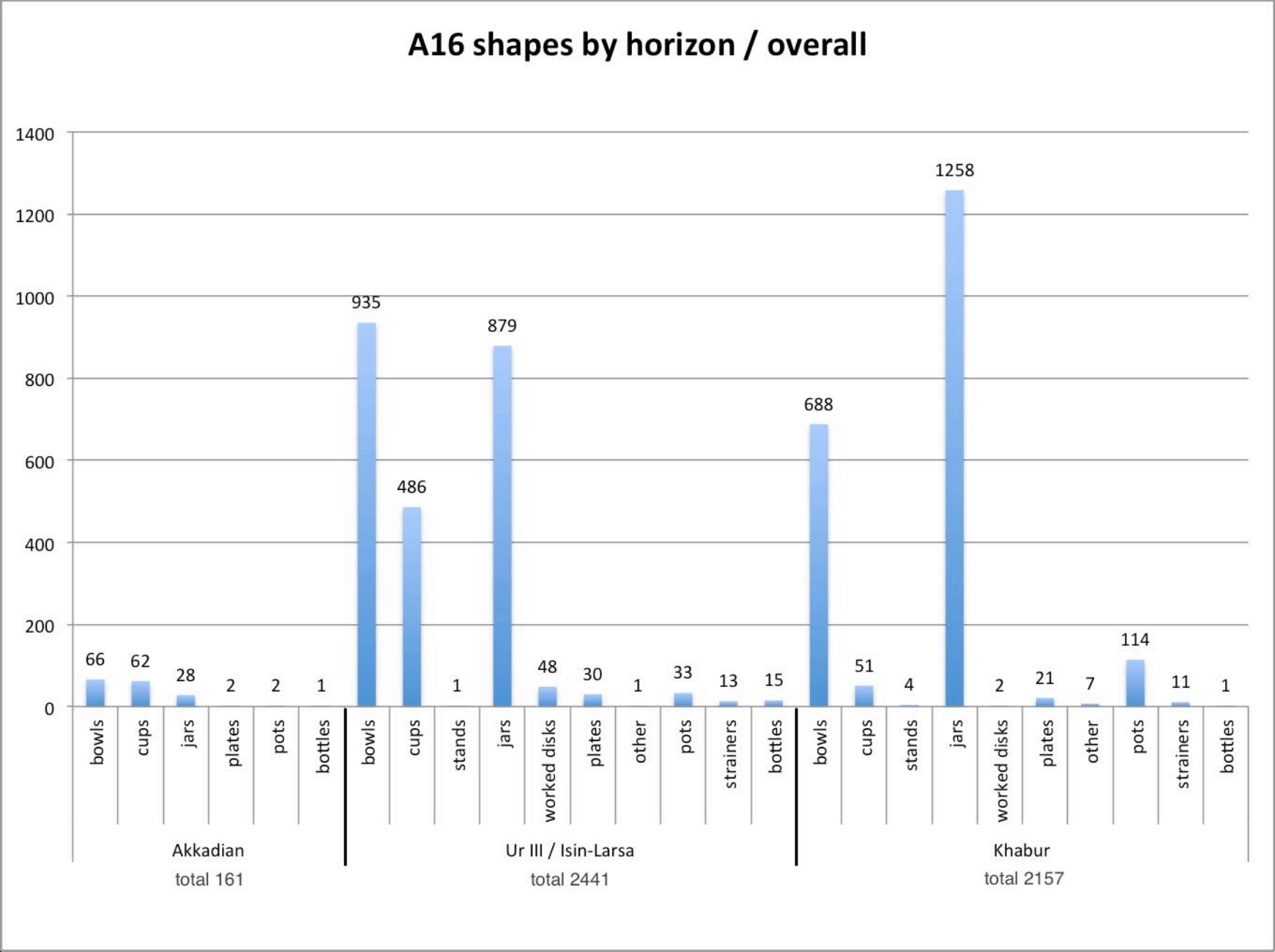
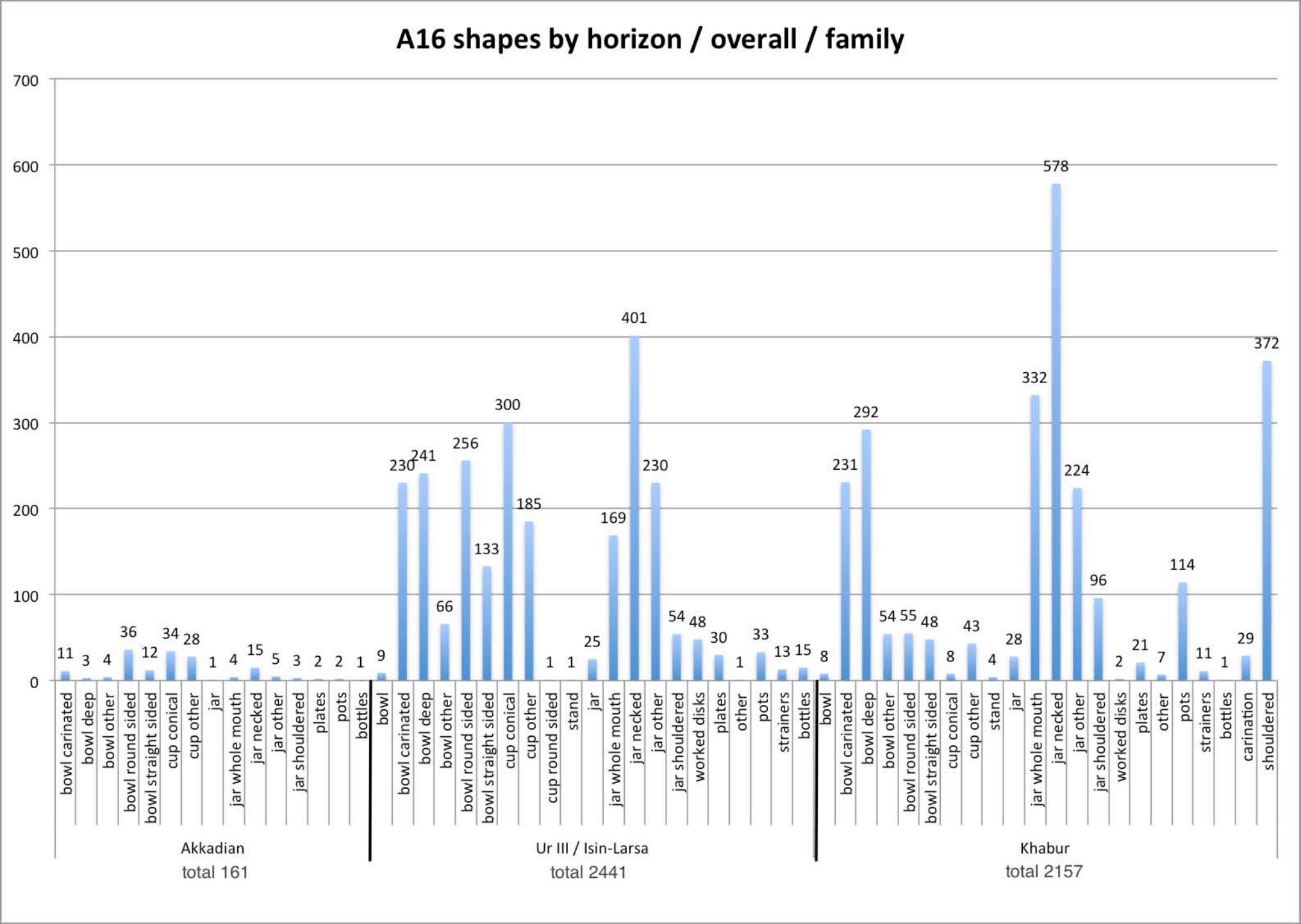
Back to top: The Urkesh Corpus
Principles of analysis
The digital nature of the publication makes it possible to include all the excavated ceramics contained in the Urkesh corpus in a publication of these ceramics and their analyses; this publication is the Urkesh Global Record. With this type of publication as our aim, the ceramics have been excavated and analyzed in a system of highly articulated categories (see also history of the project and field methodology).
The Ceramics Book is strictly tied to the field books where the individual sherds are published within their excavation context. The ceramics book describes the principles fundamental for the digital analysis, the methodology and the overall system used. The book sets out the detailed description of the ceramics through the use of highly differentiated interlinked codes describing all the attributes. So for instance on the left hand side the roster and lexicon give in detail the codes and an explanation of what they stand for. In the Attributes section on the left hand side there are sections describing in more detail the exact nature of each category in wares, shapes, decoration, color, etc.
Back to top: The Urkesh Corpus
Big data
Technically, these data do not qualify as “big data” since they can be processed with standard software. We may perhaps say, however, that these are big data perceptually, since the quantity of elements and the degree of categorization exceeds what is otherwise normal in the field.
Back to top: The Urkesh Corpus